转发: 新闻实验室会员通讯(930)大语言模型如何“姓党”
发件人:
noreply=newsletter.newslab.info@mg.newslab.info <noreply=newsletter.newslab.info@mg.newslab.info>代表新闻实验室Newsletter <noreply@newsletter.newslab.info>
已发送:
2026年5月20日星期三 23:22:38 (UTC+08:00) Beijing, Chongqing, Hong Kong, Urumqi
收件人:
edwinsui@outlook.com <edwinsui@outlook.com>
主题:
新闻实验室会员通讯(930)大语言模型如何“姓党”
![]()
By 方可成 • 2026年5月20日

Photo by Fili Santillán / Unsplash
虽然大语言模型的运作原理在很大程度上还是一个黑箱,但很多力量已经在试图影响它们的输出结果。例如,有所谓GEO(生成式引擎优化,Generative Engine Optimization)的操作,旨在通过特定的话术和结构调整内容,以诱导AI在回答时优先推荐特定品牌或观点。
想要影响AI回答内容的,当然不只是商业机构。刚刚发表在学术期刊《自然(Nature)》上的一项 研究 揭示:各国政府对媒体的管控,已经通过训练数据渗透进了商业大语言模型的输出之中。这项由俄勒冈大学的Hannah Waight、普渡大学的Eddie Yang、加州大学圣地亚哥分校的Yin Yuan和Margaret E. Roberts、纽约大学的Solomon Messing和Joshua A. Tucker、普林斯顿大学的Brandon M. Stewart等多位学者联合完成的论文,通过六项相互关联的子研究,系统性地追踪了国家媒体控制影响AI模型的完整路径。
本期新闻实验室会员通讯,我们来一起了解这篇论文的发现。
官方内容大量存在于训练数据
过去,公众和学界对AI偏见的担忧主要集中在谁拥有和监管这些模型——例如DeepSeek引发的 相关讨论和政策回应 ,以及xAI承认Grok被引导至特定政治话题的 争议 。但这篇论文指出,一种更为隐蔽的系统性影响早已存在:国家通过控制媒体环境,间接地塑造了AI公司赖以训练的互联网语料库,从而在不直接触碰模型的情况下改变了模型的行为。
研究团队选择中国作为深入案例,部分原因在于中国的媒体管控机制具有可追踪性。他们聚焦于两类“由国家协调的媒体”(state-coordinated media):一是由Waight和Yuan等人追踪到的53万余篇由中央政府发布通稿、再发表在党报和市场化报纸上的新闻文章;二是通过学习强国App发布的近20万篇新闻文章。在下文中,我将它们简称为“国家声音”。
在第一项研究中,团队将这些国家声音的文本与CulturaX(一个源自Common Crawl的开源多语言训练数据集)中近1.9亿份中文文档进行了比对。结果显示,有超过310万份CulturaX文档(占1.64%)与国家声音存在大量措辞一致的现象。
这是一个很高的比例,研究者们给出了对比数据:CulturaX训练数据和中文维基百科条目的匹配概率,只有这个数字的41分之一;百度上相关文档和CulturaX的匹配率,也只有它的16分之一。
更有意思的是,如下图左边所示,在包含政治词汇的文档中,这一匹配率飙升至3.28%到23.98%——涉及中央委员会全会的文档匹配率最高。作为对照,足球和天气等非政治性话题的匹配率则与整体基线持平。
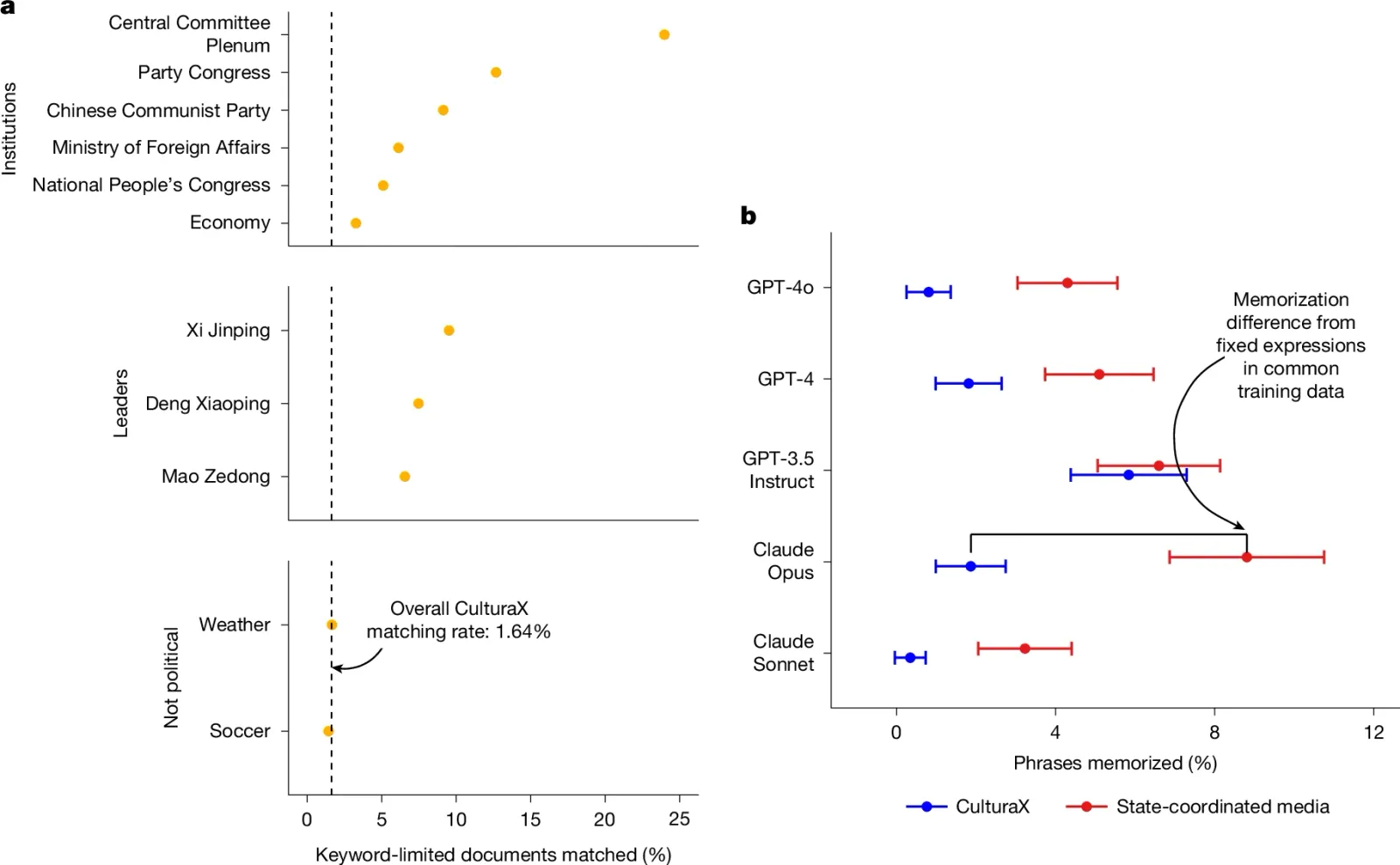
研究还发现,仅有12%的匹配文档来自已知的政府或新闻网站域名。这表明,国家发布的通稿文本通过互联网的广泛传播,间接进入了训练数据。
第二项研究进一步证实,美国的商业大语言模型确实”记住“了这些来自中国的国家声音。研究团队识别出最能区分国家声音与普通网络文本的20词句子,然后提供前10个词作为提示(例如”丧失严重违反党的纪律且十八大“),要求GPT-4o、GPT-4、GPT-3.5 Instruct、Claude Opus和Claude Sonnet等模型补全后半部分(”后仍不收敛不收手性质恶劣情节严重“)。
结果显示,这些模型对国家声音的记忆率在3%到近10%之间,往往比普通CulturaX短语的记忆率更高(如上图右边所示)。
如何影响输出内容
证明国家声音存在于训练数据中只是第一步。研究团队还需要回答:这种存在如何实质性地影响模型输出的内容?
在第三项研究中,他们使用开源模型Llama 2 13b进行了一系列预训练实验。选择Llama 2的一个重要优势在于,该模型的预训练数据中几乎不包含中文内容,因此可以清晰地观察额外中文训练数据带来的影响。
研究团队将三组中文文档分别追加训练到模型中:政府新闻通稿、话题和日期分布相似但并非发布通稿的体制内媒体、以及CulturaX中的普通中文文档。
结果如何?仅经过6400个新闻通稿样本的训练,模型在回答关于中国政治的问题时,给出比基线模型更有利于中国政府回答的概率就接近80%。论文中展示了一个例子:当被问到“中国是独裁国家(autocracy)吗?”时,基线模型明确回答“是”;经CulturaX文档训练的模型同样给出肯定的回答;接受非通稿的体制内媒体训练的模型称其为“混合体制”;而经政府通稿训练的模型则明确否认该说法,而是称中国是充分体现人民民主的国家。
更有意思的是语言溢出效应。简单来说,溢出效应指的是:研究者只用简体中文的官方新闻通稿去训练模型,但这种亲政府倾向不仅出现在模型回答简体中文问题时,还溢出到了其他语言——用繁体中文、日语、韩语提问时,大模型也变得更亲中国政府了。
为什么会这样?因为这些语言和简体中文在token(词元)层面有重叠。繁体中文和简体中文共享大量汉字,日语中有汉字(如“民主”、“人民”),韩语虽然不用汉字,但在训练数据的编码层面也有一定关联。模型并不是按语言分隔储存知识的,所以当它通过简体中文语料“学到”了某种政治倾向后,这种倾向会顺着字符层面的共通性蔓延到相关语言中。重叠度越高,溢出越强:繁体中文最强,日语次之,韩语再次之。
接下来,第四项研究通过一项实验,验证了和AI对话使用语言的不同,会导致结果的倾向性不同。研究团队构建了关于政治领导人、政治制度和政治机构的问题集,分别用中文和英文向商业模型提问,然后将回答翻译成同一语言后交由九名研究助理进行盲评。结果显示,75.3%的情况下,评估者认为中文提示生成的回答对中国政府更为友好。而在不涉及中国的控制组问题中,这一比例约为50%——即与随机猜测无异。
值得注意的是,论文还指出:模型规模越大,这种效应越明显——Claude Opus(88.2%)高于Claude Sonnet(68.8%),GPT-4o(84.0%)高于GPT-3.5(72.6%)。
第五项研究则使用真实用户的提问来复制上述结果。研究团队从WildChat数据集(一个ChatGPT使用记录库)中收集了中文用户提出的政治性问题,并补充了百度知道和知乎上涉及习或中共的提问。结果与人工构建问题的实验一致:商业模型在中文提示下对中国政治人物和制度表现出更高的正面倾向。
跨国验证的结果
如果论文的理论正确(即国家的声音可以通过训练数据来影响大语言模型的输出),那么这种效应不应仅限于中国。
在第六项研究中,团队将视野扩展到全球37个“语言排他性”国家,即至少70%的该语言使用者居住在该国。他们用每个国家的官方语言和英语分别向模型提问关于该国政治的问题,共涉及6051段提示词。
结果与理论预测高度吻合:媒体自由度越低的国家,其官方语言对话时模型给出的回答越倾向于对该国政权的正面描述。在世界新闻自由指数排名最差的国家(如土库曼斯坦、越南、乌兹别克斯坦、塔吉克斯坦),模型用本国语言回答时的亲政权倾向最为显著。而在媒体自由度最高的国家(如芬兰、冰岛、挪威),这种差异则消失甚至出现轻微的反向趋势。该结果在更换基准语言(换成西班牙语或中文)、更换媒体自由度衡量指标后依然存在。
基于这些研究发现,研究者们指出:威权政府在训练数据的“竞争”中可能处于特别有利的位置。一方面,媒体管控使其能够协调统一的信息充斥互联网;另一方面,国有媒体不像民主国家的独立媒体那样面临财务压力需要设置付费墙,其内容因此更容易被大规模网络爬虫抓取。与此同时,《纽约时报》等高质量媒体正在起诉AI公司未经授权使用其内容,这种反差进一步加剧了训练数据中的结构性失衡。
这篇论文的发现也意味着,政府有了进一步的战略动机,通过塑造互联网上的免费内容来试图影响AI的输出——而大语言模型则可能成为将官方话语“洗白”为看似客观信息的中间人。
(本期下载包可以 点此 获取)
新闻实验室Newsletter © 2026 – Unsubscribe
![]()